
词性标注(Part-of-Speech Tagging, 简称POS tagging)是将句子中的每个词做一些标记,如动词,名词,副词,形容词等。词性很有用,因为它们揭示了一个单词及其相邻词的很多信息。知道一个单词是名词还是动词可以告诉我们可能的相邻单词(名词前面有限定词和形容词,动词前面有名词)和句法结构单词(名词通常是名词短语的一部分)。一个单词的词性甚至可以在语音识别或合成中发挥作用,因为有些单词不同词性时的读音是不同的。在本综述中,将讨论词性标注的相关算法,比如早期的隐马尔可夫模型 (Hidden Markov Model, HMM)和随机条件域 (Conditional Random Fields, CRF),以及近几年的神经网络。
1 介绍
词性标注的研究始于20世纪60年代初。词性标注是自然语言处理的重要工具。它是许多NLP应用程序中最简单的统计模型之一。词性标注是信息提取、归纳、检索、机器翻译、语音转换的初始步骤。在上世纪80年代末,人们使用基于隐马尔可夫模型已经使词性标注已经最高达到了95%的准确度。而最近几年,由于神经网络的完善和推广,有些模型可以达到97%的准确度。
2 早期算法
早期解决词性标注问题以隐马尔可夫模型算法为主。
2.1 HMM
HMMs和随机语法被广泛应用于文本和语音处理的各种问题,包括主题分割、词性标注、信息提取和句法消歧。
在计算语言学和计算机科学中,隐马尔可夫模型(Hidden Markov models, HMMs)和随机语法被广泛应用于文本和语音处理的各种问题,包括主题分割、词性标注、信息提取和句法消歧。
2.1.1 Hidden Markov Model
马尔可夫链是一个模型,它告诉我们随机变量序列的概率。这些集合可以是表示任何东西的单词、标记或符号,例如天气。马尔可夫链有一个重要的假设,如果我们想在序列中预测未来,重要的是当前状态,当前状态之前的所有状态对未来都没有影响。就好像要预测明天的天气,你可以检查今天的天气,但是你不允许查看昨天的天气。
而马尔可夫假设(Markov Assumption)表示为,
\[ P(q_i=a|q_1 ...q_{i-1} ) = P(q_i=a|q_{i-1} ) \]
规定,离开给定状态的弧的值之和必须为1。一种马尔可夫链,用于为单词序列\(w_1...w_n\)分配一个概率,它表示一个双语言模型,每条边表示概率\(p(w_i|w_j)\)。
- \(Q=q_1q_2...q_N\) 表示N个状态的集合。
- \(A=a_{12}a_{12}...a_{n1}...a_{nm}\) 一个转移概率矩阵。\(a_{ij}\) 表示状态\(i\)到状态\(j\)的概率。
- \(\pi=\pi_1\pi_2...\pi_N\) 一个开始概率分布。
隐马尔可夫模型,即我们不直接观测状态。例如,我们通常不会在文本中观察词性标记。相反,我们看到单词,必须从单词序列中推断出标记。我们将这些标记称为隐藏标记,因为它们没有被观察到。
- \(Q=q_1q_2...q_N\) 表示N个状态的集合。
- \(A=a_{12}a_{12}...a_{n1}...a_{nm}\) 一个转移概率矩阵。\(a_{ij}\) 表示状态\(i\)到状态\(j\)的概率。
- \(O=o_1o_2...o_N\) 序列\(T\)的观测。
- \(B=b_i(o_t)\) 表示由状态\(i\)产生的观测值\(o_t\)的概率
- \(\pi=\pi_1\pi_2...\pi_N\) 一个开始概率分布。
第二个假设:输出观测\(o_i\)的概率只取决于产生观测\(q_i\)的状态,而不取决于任何其他状态或任何其他观测:
\[ P(o_i|q_1...q_{i-1}) = P(o_i|q_{i-1}) \]
2.1.2 HMM 标记器
对我们的语料库构建一个词性转移概率矩阵\(A\),包含\(P(t_i|t_{i-1})\),表示给定前一个标记得到当前标记的概率,比如像will这样的情态动词后面很可能跟一个基本形式的动词。
而构建这样的词性转移概率矩阵,需要统计语料库中的词性转移次数,
\[ P(t_i|t_{i-1}) = \frac{C(t_{i-1},t_i)}{C(t_{i-1})} \]
比如,MD在WSJ语料库中出现的次数是13124,而MD之后出现will的次数为4046,
\[ P(will|MD) = \frac{C(MD,will)}{C(MD)} = \frac{4046}{13124} = 0.31 \]
2.1.3 HMM 解码器
解码器的定义是:输入一个HMM \(\lambda=(A, B)\) 和观测\(O=o_1o_2...o_N\),找到最有可能的状态序列 \(Q=q_1q_2...q_N\)。
n个单词的序列\(w^n\),标记序列\(t^n\),则最终序列结果\(\hat{t}^n\)由:
\[ \hat{t}^n = \mathop{argmax}_{t^n}P(t^n|w^n) \]
有贝叶斯定理可得:
\[ \hat{t}^n = \mathop{argmax}_{t^n}\frac{P(w^n|t^n)P(t^n)}{P(w^n)} \]
为了简化公式,去掉分母,
\[ \hat{t}^n = \mathop{argmax}_{t^n}P(w^n|t^n)P(t^n) \]
根据第一个假设可知,一个标记只取决于前一个标记。
\[ P(t^n) \approx \prod_{i=1}^n P(t_i|t_{i-1}) \]
根据第二个假设可知,一个单词(观测)依赖于自身的标记(状态)以及相邻单词及其标记,可得
\[ P(w^n|t^n) \approx \prod_{i=1}^n P(w_i|t_i) \]
最终可得,
\[ \hat{t}^n = \mathop{argmax}_{t^n}P(t^n|w^n) \approx \mathop{argmax}_{t^n} \prod_{i=1}^n P(w_i|t_i)P(t_i|t_{i-1}) \]
2.1.4 The Viterbi Algorithm
维特比算法建立一个概率矩阵或格子(lattice),这个格子,的每一列表示一个观测,而每一行表示一个状态。
对于格子中的每一个单元格 \(v_t(j)\) 表示HMM \(\lambda\) 经过了\(t\)个观测来到状态\(j\)中。
\[ v_t(j)=\mathop{max}_{q_1...q_{t-1}}P(q_1...q_{t-1},o_1,o_2...o_t,q_t=j|\lambda) \]
其中\(q_1...q_{t-1}\)表示该单元格经过的所有状态,我们需要像动态规划那样最大化这个状态序列,以便于最终取得最优值。

可得迭代公式,
\[ v_t(j)=\mathop{max}^N_{i=1}v_{t-1}(i)a_{ij}b_j(o_t) \]
2.2 CRF
HMMs和随机语法是生成模型,将联合概率分配给成对的观察和标签序列。为了定义观测序列和标号序列的联合概率,生成模型需要枚举所有可能的观测序列。特别是,表示多个相互作用的特征或观测值的长期依赖关系是不现实的,因为这类模型的推理问题是难以解决的。
条件随机域 (conditional random fields, CRF) (Lafferty, McCallum & Pereira, 2001)是一个单一的指数模型,可以计算得到给定观测序列的整个标签序列的联合概率。
我们用\(z = {z_1,..., z_n}\)表示一个通用的输入序列,\(z_i\) 表示第\(i\)个单词的向量。\(y={y_1,...,y_n}\) 表示\(z\)的标签。\(\mathcal{Y}(z)\) 表示\(z\)的标签序列集。序列的条件随机域定义为一个条件概率模型 \(p(y|z;W,b)\)。给定\(z\)与所有可能的\(y\)组成:
\[ p(y | z ; W, b)=\frac{\prod_{i=1}^{n} \psi_{i}\left(y_{i-1}, y_{i}, z\right)}{\sum_{y^{\prime} \in \mathcal{Y}(z)} \prod_{i=1}^{n} \psi_{i}\left(y_{i-1}^{\prime}, y_{i}^{\prime}, z\right)} \]
其中,\(\psi_{i}\left(y_{i-1}, y_{i}, z\right) = \exp \left(W_{y^{\prime}, y}^{T} z_{i}+b_{y^{\prime}, y} r\right)\) ,而 \(W_{y^{\prime}, y}^{T}\) 与 \(b_{y^{\prime}, y}\) 分布为权重向量和对应标签对的偏移。
对于CRF训练,我们使用最大条件似然估计:
\[ L(W, {b})=\sum_{i} \log p(y | {z} ; {W}, {b}) \]
只要最大化 \(L(W, {b})\) 即可。
而解码过程就是搜索具有最高条件概率的标签序列 \(y^*\):
\[ {y}^{*}=\underset{y \in \mathcal{Y}({z})}{\operatorname{argmax}}\; p({y} | {z} ; {W}, {b}) \]
3 神经机器学习
早期算法HMM,CRF等严重依赖手工制作的特性和特定于任务的资源。这种特定于任务的知识开发成本很高,使得序列标记模型难以适应新任务或新领域。近年来,作为输入分布式词表示的非线性神经网络,也称为词嵌入,在NLP问题中得到了广泛的应用,并取得了很大的成功。最近,递归神经网络(RNN) (Goller and Kuchler, 1996) 及其变体,如长短时记忆(LSTM) (Hochreiter and Schmidhuber, 1997)和门控循环神经单元 (GRU) (Cho et al., 2014)在序列数据建模方面取得了巨大的成功。
3.1 LSTM
递归神经网络(RNNs)是一个强大的连接主义模型家族,它通过图中的周期来捕捉时间动态。虽然在理论上,RNNs能够捕获远程依赖关系。但在实践中,由于梯度消失/爆炸问题,基本上失败了。
LSTMs (Hochreiter and Schmidhuber, 1997) 是RNNs的变体,用于处理这些梯度消失问题。基本上,LSTM单元由三个乘法门组成,它们控制信息的比例,以便遗忘和传递到下一个时间步骤。
形式上,LSTM单元在 \(t\) 时间步更新的公式为:
\[ \begin{aligned} \mathbf{i}_{t} &=\sigma\left(\boldsymbol{W}_{i} \mathbf{h}_{t-1}+\boldsymbol{U}_{i \mathbf{x}_{t}}+\boldsymbol{b}_{i}\right) \\ \mathbf{f}_{t} &=\sigma\left(\boldsymbol{W}_{f} \mathbf{h}_{t-1}+\boldsymbol{U}_{f} \mathbf{x}_{t}+\boldsymbol{b}_{f}\right) \\ \tilde{\mathbf{c}}_{t} &=\tanh \left(\boldsymbol{W}_{c-1} \mathbf{h}_{t-1}+\boldsymbol{U}_{c} \mathbf{x}_{t}+\boldsymbol{b}_{c}\right) \\ \mathbf{c}_{t} &=\mathbf{f}_{t} \odot \mathbf{c}_{t-1}+\mathbf{i}_{t} \odot \tilde{\mathbf{c}}_{t} \\ \mathbf{o}_{t} &=\sigma\left(\boldsymbol{W}_{o} \mathbf{h}_{t-1}+\boldsymbol{U}_{o} \mathbf{x}_{t}+\boldsymbol{b}_{o}\right) \\ \mathbf{h}_{t} &=\mathbf{o}_{t} \odot \tanh \left(\mathbf{c}_{t}\right) \end{aligned} \]
其中 \(\sigma\) 表示 sigmoid 函数,\(\odot\) 表示点积,\(x_t\) 是在 \(t\) 时间步的输入向量,\(h_t\) 是隐藏状态向量,包含了当前及前面所有时间步的信息。\(U_i, U_f, U_c, U_o\) 表示不同门的输入权重矩阵。而\(W_i, W_f, W_c, W_o\)表示不同门的隐藏状态权重矩阵,\(b_i, b_f, b_c, b_o\) 表示偏移向量。
3.1.1 双向 LSTM (BLSTM)
对于许多序列标记任务,访问过去(左)和未来都是有益的。然而,单向LSTM的隐藏状态\(h_t\)只从过去获取信息,对未来一无所知。一个优雅的解决方案是双向LSTM,其有效性已经被之前的工作证明 (Chiu et al., 2016)。其通过向前和向后传播的两个隐藏状态,分别捕获过去和未来的信息,然后将这两个隐藏状态连接起来,形成最终的输出。
3.2 用于字符级表示的CNN
卷积神经网络(CNN)是一种从单词字符中提取形态学信息(如单词的前缀或后缀)并将其编码成神经表示的有效方法 (Ma, & Hovy, 2016)。Figure 1 展现了用CNN提取给定单词的字符级表示。
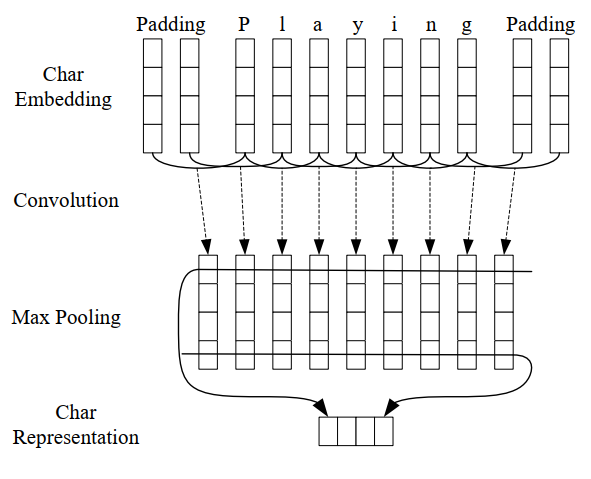
用CNN计算出每个单词的字符级表示,然后字符级向量表示连接词级向量组成最终的输入向量。
4 训练与评估
词嵌入。 常使用斯坦福大学公开的GloVe 嵌入式系统,该系统训练了来自维基百科和网络文本的60亿个单词 (Pennington et al., 2014)。
数据集。 常使用宾夕法尼亚大学的《华尔街日报》部分 Treebank (PTB) (Marcus et al., 1993),其中包含45个不同的POS标签。并分为训练集和测试集。而准确度标准采用F1分数。
| Mocel | Acc. |
|---|---|
| Bi-LSTM (Plank et al., 2016) | 97.22 |
| Feed Forward (Vaswani et a. 2016) | 97.4 |
| NCRF++ (Yang and Zhang, 2018) | 97.49 |
| LSTM-CNNs-CRF (Ma and Hovy, 2016) | 97.55 |
| Adversarial Bi-LSTM (Yasunaga et al., 2018) | 97.59 |
| Meta BiLSTM (Bohnet et al., 2018) | 97.96 |
Table 1: 近几年的各种模型的测试结果。
5 目前与未来研究
过去以及目前,很多模型都字符级或词级的词嵌入来改善模型性能,还有一些是通过优化语言模型来助力提高词性标注的准确性。未来,一种可能是会通过预训练的强大语言模型或词嵌入来继续提高词性标注性能;二是提出一种新型的网络模型来产生突破性的成果。
参考
- Lafferty, J., McCallum, A., & Pereira, F. (2001). Conditional Random Fields: Probabilistic Models for Segmenting and Labeling Sequence Data.
- Goller, C., & Kuchler, A. (1996, June). Learning task-dependent distributed representations by backpropagation through structure. In Proceedings of International Conference on Neural Networks (ICNN'96) (Vol. 1, pp. 347-352). IEEE.
- Hochreiter, S., & Schmidhuber, J. (1997). Long short-term memory. Neural computation, 9(8), 1735-1780.
- Cho, K., Van Merriënboer, B., Bahdanau, D., & Bengio, Y. (2014). On the properties of neural machine translation: Encoder-decoder approaches. arXiv preprint arXiv:1409.1259.
- Chiu, J. P., & Nichols, E. (2016). Named entity recognition with bidirectional LSTM-CNNs. Transactions of the Association for Computational Linguistics, 4, 357-370.
- Ma, X., & Hovy, E. (2016). End-to-end sequence labeling via bi-directional lstm-cnns-crf. arXiv preprint arXiv:1603.01354.
- Pennington, J., Socher, R., & Manning, C. (2014). Glove: Global vectors for word representation. In Proceedings of the 2014 conference on empirical methods in natural language processing (EMNLP) (pp. 1532-1543).
- Marcus, M., Santorini, B., & Marcinkiewicz, M. A. (1993). Building a large annotated corpus of English: The Penn Treebank.
- Plank, B., Søgaard, A., & Goldberg, Y. (2016). Multilingual part-of-speech tagging with bidirectional long short-term memory models and auxiliary loss. arXiv preprint arXiv:1604.05529.
- Vaswani, A., Bisk, Y., Sagae, K., & Musa, R. (2016). Supertagging with lstms. In Proceedings of the 2016 Conference of the North American Chapter of the Association for Computational Linguistics: Human Language Technologies (pp. 232-237).
- Yang, J., & Zhang, Y. (2018). Ncrf++: An open-source neural sequence labeling toolkit. arXiv preprint arXiv:1806.05626.
- Yasunaga, M., Kasai, J., & Radev, D. (2017). Robust multilingual part-of-speech tagging via adversarial training. arXiv preprint arXiv:1711.04903.
- Bohnet, B., McDonald, R., Simoes, G., Andor, D., Pitler, E., & Maynez, J. (2018). Morphosyntactic tagging with a meta-bilstm model over context sensitive token encodings. arXiv preprint arXiv:1805.08237.
Comments